

前言
这一篇文章, 是对leetcode上部分SQL题目(14/19)的解析, 所有的题目均使用MySQL的语法。这些题目的SQL的写法可能不是最优的, 但是它们都通过了leetcode上的所有的测试用例, 如果你有更好的SQL请务必联系我, 🐧: 1025873823。leetcode上的SQL类的题目不是很多, 只有19题。很遗憾, 我没有将它们全部攻克。未来我会尝试将它们全部解答出来。
题目1: 组合两张表
组合两张表, 题目很简单, 主要考察JOIN语法的使用。唯一需要注意的一点, 是题目中的这句话, “无论 person 是否有地址信息”。说明即使Person表, 没有信息我们也需要将Person表的内容进行返回。所以我选择使用左外查询, 当然你也可以选择RIGHT OUTER JOIN, 这取决于你查询语句的写法。
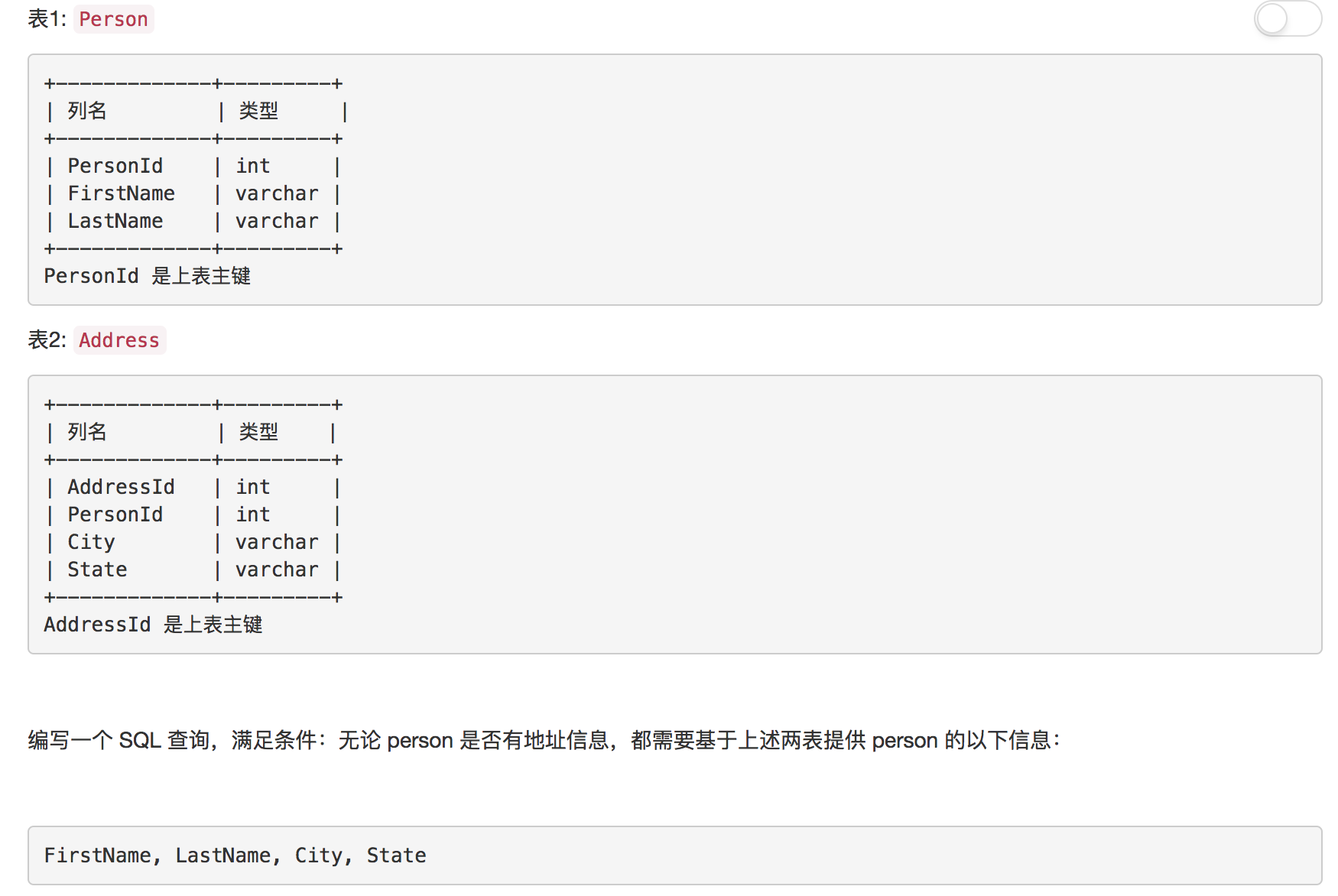
解答
SELECT Person.FirstName, Person.LastName, Address.City, Address.State
FROM Person LEFT OUTER JOIN Address ON Person.PersonId = Address.PersonId
题目2: 第二高的薪水
第二高的薪水, 题目本身并不难, 但是请注意, 题目中的描述**“如果不存在第二高的薪水,那么查询应返回 null”**, 这意味着, 如果SQL没有查询到结果, SQL本身需要一个默认的返回值。如何才能做到, 即使没有结果也返回一个值。通过谷歌, 我查找到了解决方案Returning a value even if no result 。使用IFNULL函数, 并且将整个SQL语句作为IFNULL函数的参数。如果IFNULL函数第一个的参数为NULL, 则返回IFNULL函数的第二个参数, 否则返回第一个参数。
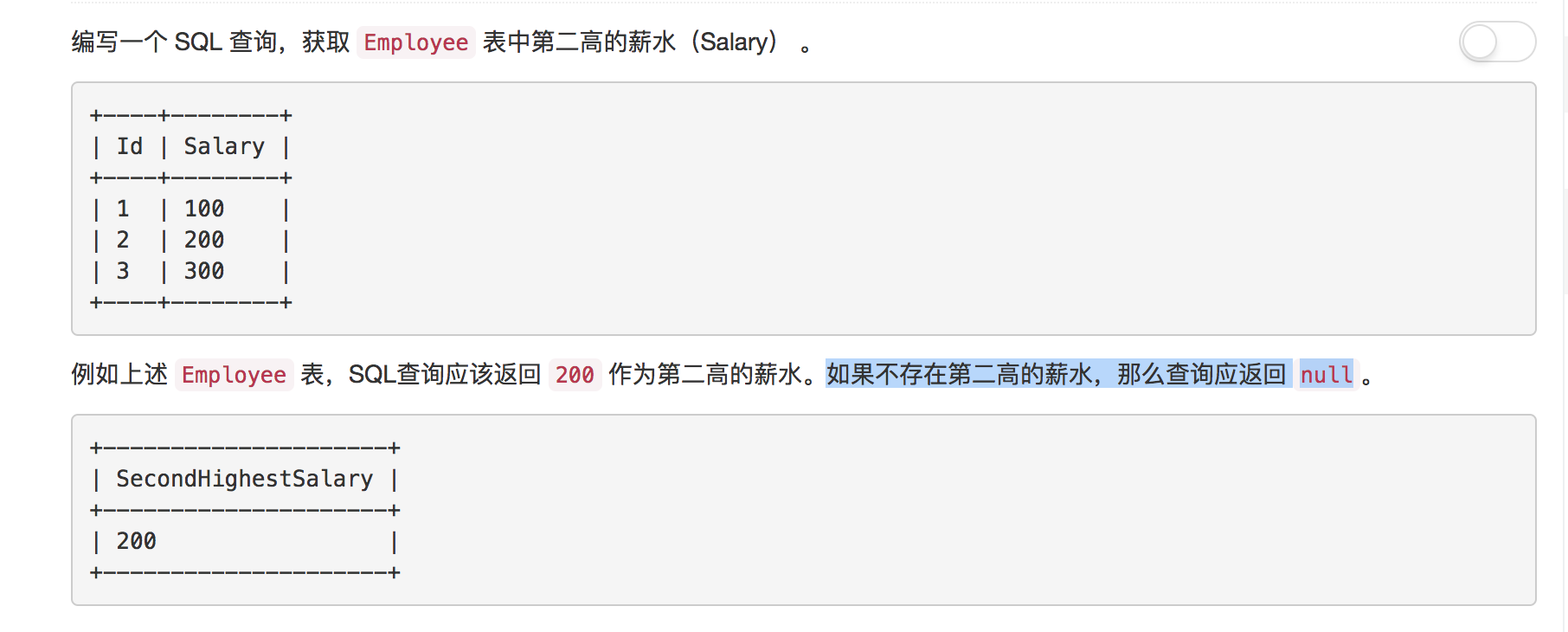
解答
SELECT IFNULL(
(
SELECT Employee.Salary
FROM Employee
GROUP BY Employee.Salary
ORDER BY Employee.Salary DESC
LIMIT 1 OFFSET 1
),
NULL
) AS SecondHighestSalary;
题目3: 分数排名
本题主要考察了, 如何在SQL查询中生成序号, 因为在表中本身是不含有RANK字段的。我通过谷歌, 在stackoverflow上找到了答案, Generate serial number in mysql query。
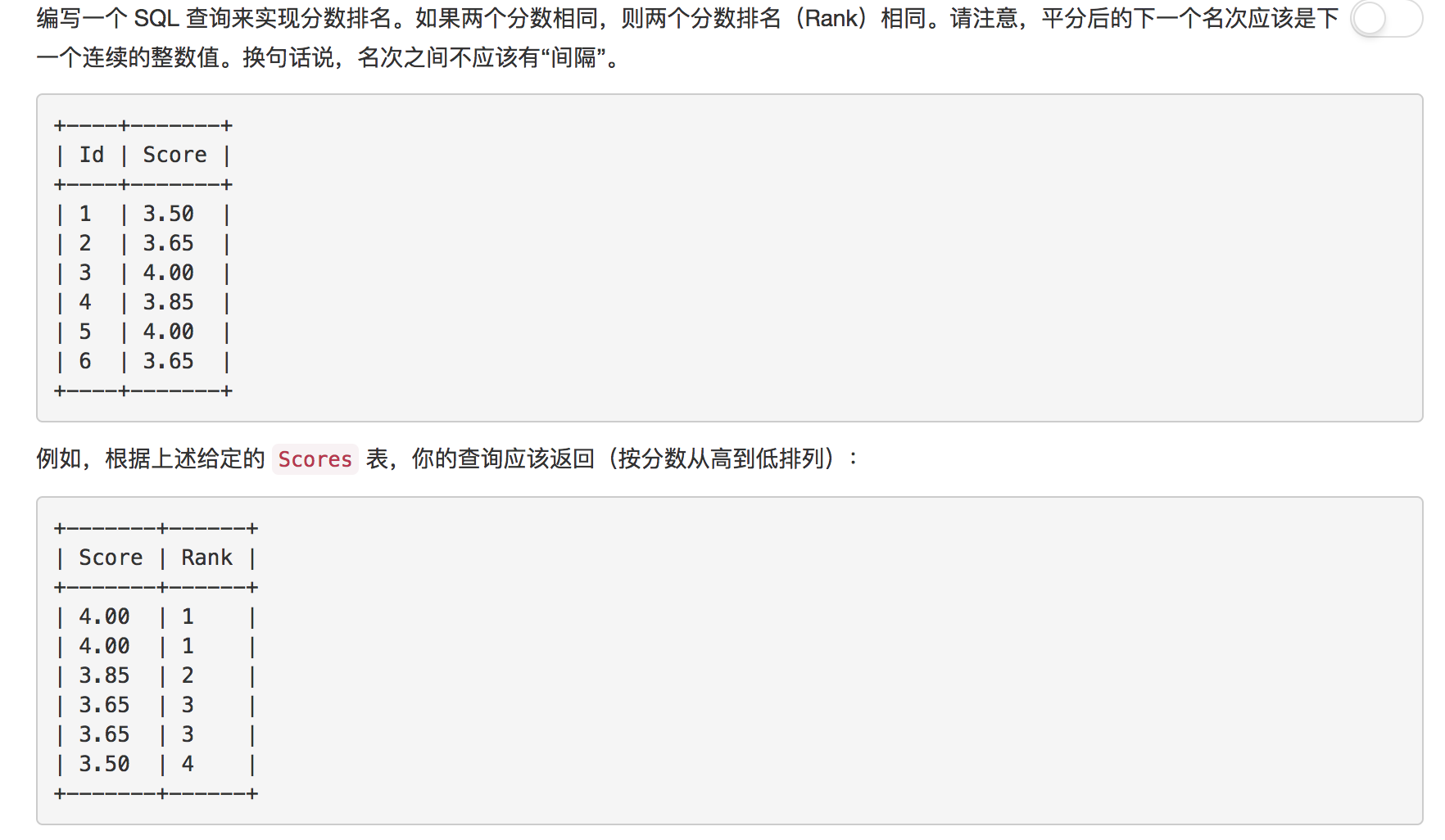
为查询结果添加序号

解答
# 3. 通过INNER JOIN为没有去重的分数表添加名次的字段
SELECT Scores.Score, RANKINDEX.rank AS RANK
FROM Scores INNER JOIN (
# 2. 为排序去重后分数表, 添加名次字段(序号)
SELECT RANK.Score AS Score, @a:=@a+1 rank
FROM (
# 1. 首先排序并去重分数表
SELECT DISTINCT Scores.Score
FROM Scores
ORDER BY Scores.Score DESC
) RANK, (SELECT @a:=0) AS a
) AS RANKINDEX
ON RANKINDEX.Score = Scores.Score
ORDER BY Scores.Score DESC
题目4: 超过经理收入的员工
非常简单的一道题目, 这里不在多做解释
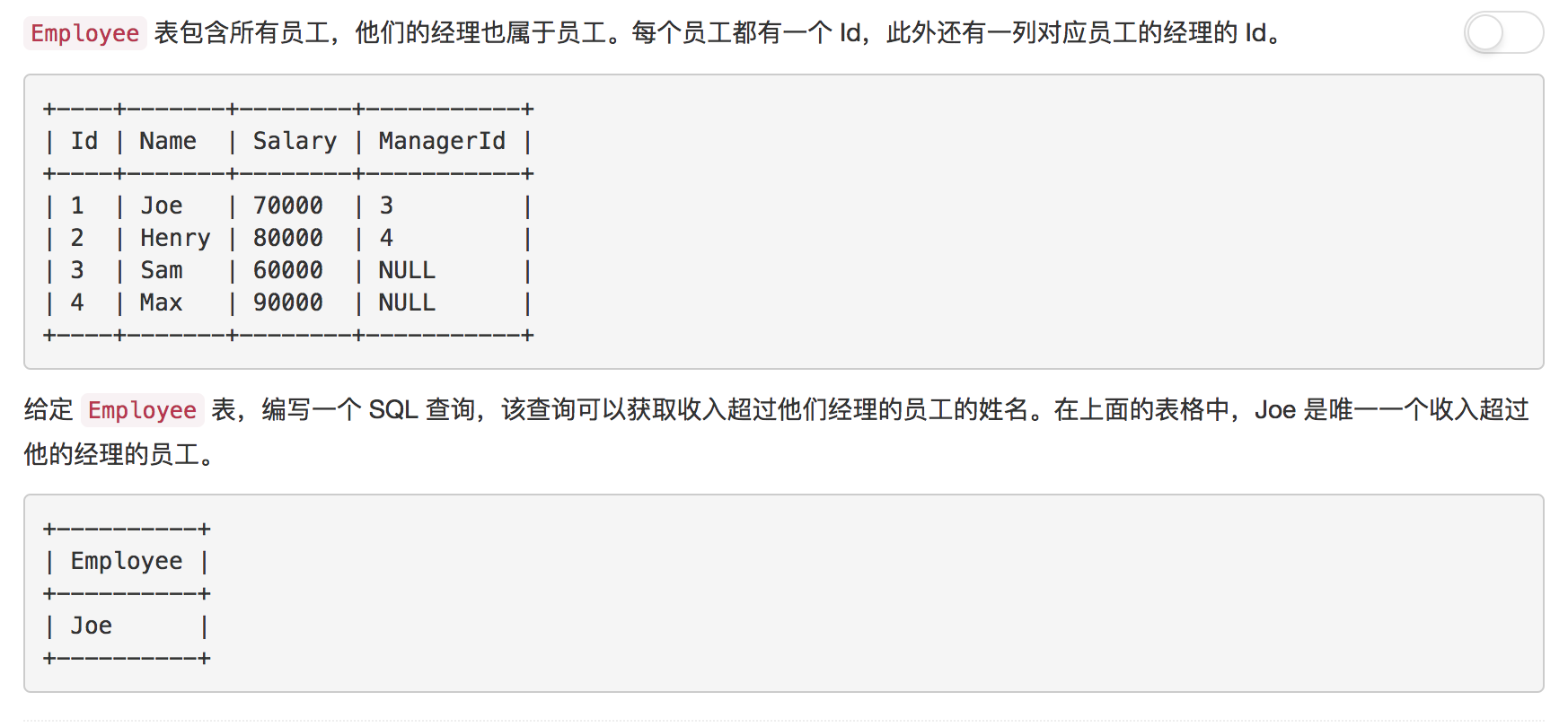
解答
SELECT emp1.Name AS Employee
FROM Employee AS emp1, Employee AS emp2
WHERE emp1.ManagerId = emp2.Id AND emp1.Salary > emp2.Salary
题目5: 查找重复的电子邮箱
同样是非常简单的一道题目, 唯一可能需要了解的就是, GROUP BY Person.Email的字句, 可以对Person.Email字段起到去重的作用
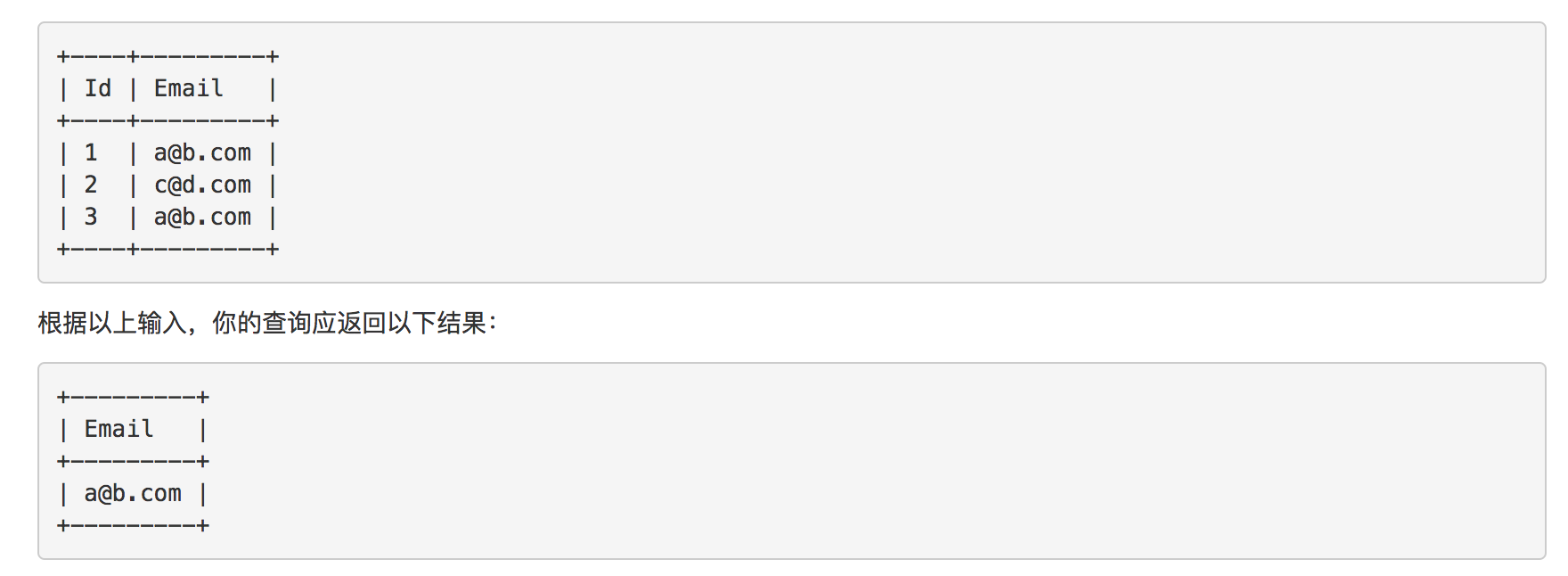
解答
SELECT Person.Email AS Email
FROM Person
GROUP BY Person.Email
HAVING COUNT(Person.Email) > 1
题目6: 从不订购的客户
依然是非常简单的一道题目, 主要考察对子查询的使用
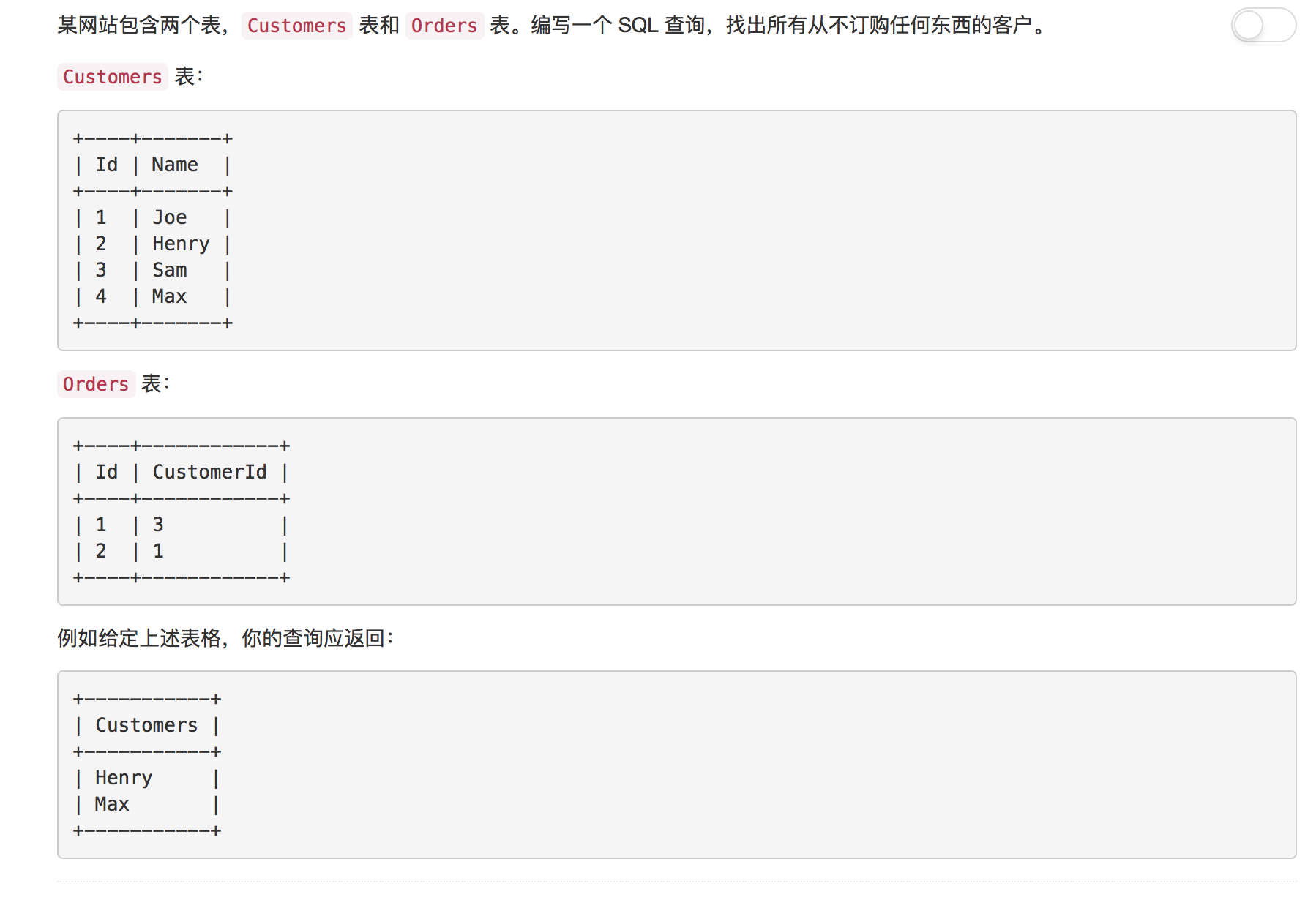
解答
SELECT Customers.Name AS Customers
FROM Customers
WHERE Customers.Id NOT IN (
SELECT Orders.CustomerId FROM Orders
)
题目7: 部门工资最高的员工
部门工资最高的员工, 在对这一题目进行解答之前。我们需要明确知道一点。“除聚合, 计算语句外,SELECT语句中的每个列都必须在GROUP BY子句中给出”。也就是说, 我们并不能在求, 每一个部门工资的Max最大值的时候, 把员工的id也计算出来。
对于这道题目,我们解答的步骤分为两步, 1. 求出每一个部门对应的最高工资, 并且将结果存储为派生表 2. 根据员工的部门id, 以及员工的工资, 与派生表联结, 比较对应员工的工资是否等于派生表的部门的最高工资。如果等于, 此人的工资就是部门的最高工资
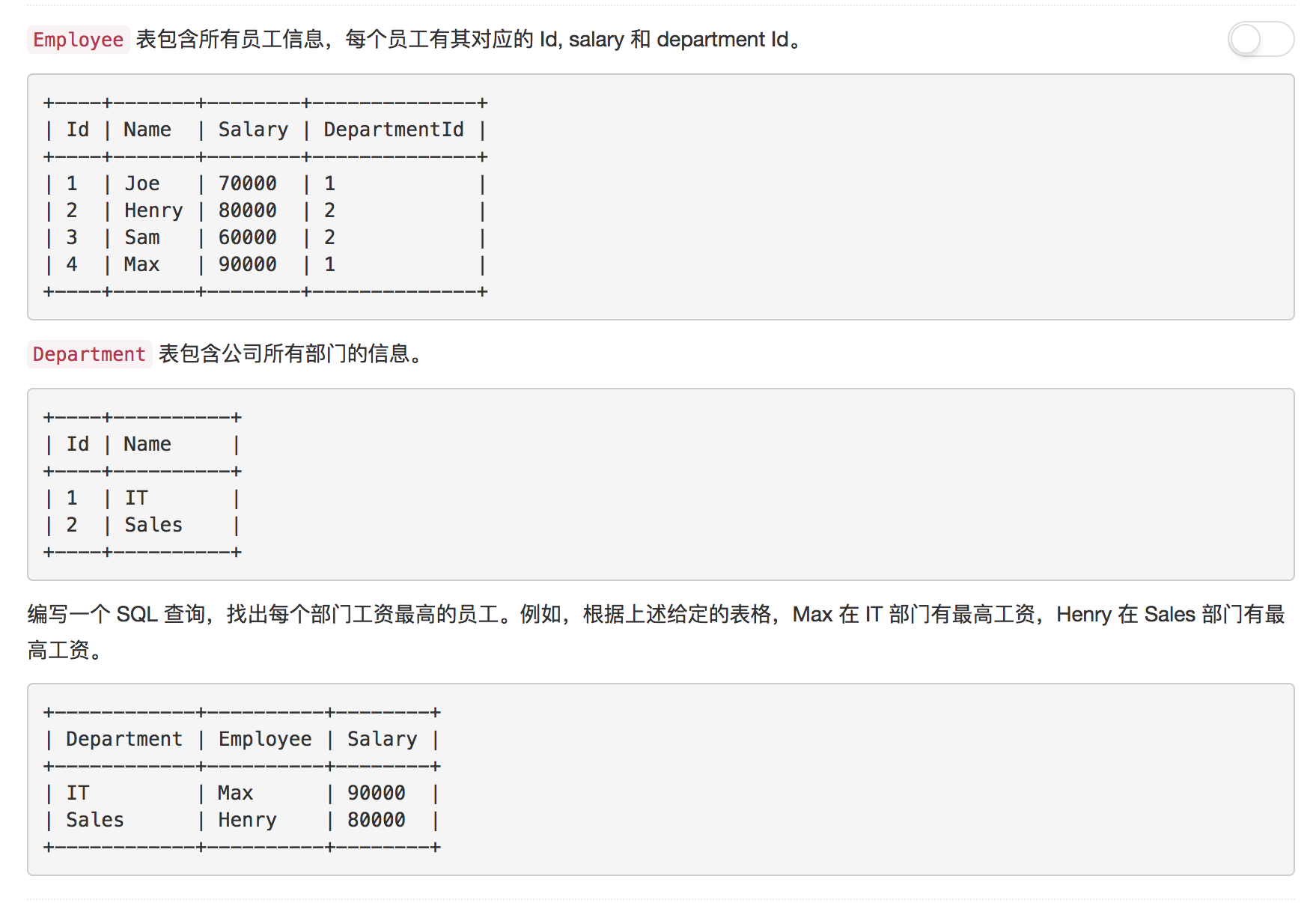
解答
SELECT Department.Name AS Department, Employee.Name AS Employee, Employee.Salary AS Salary
FROM Employee INNER JOIN Department INNER JOIN (
# 第一步求出每一个部门的最高工资, 并作为派生表使用
SELECT Max(Employee.Salary) AS Salary, Department.Id AS DepartmentId
FROM Employee INNER JOIN Department
ON Employee.DepartmentId = Department.Id
GROUP BY Employee.DepartmentId
) AS DepartmentBigSalary
# 三张表进行联结
ON Employee.DepartmentId = Department.Id AND Department.Id = DepartmentBigSalary.DepartmentId
# 比较对应员工的工资是否等于派生表的部门的最高工资
WHERE Employee.Salary = DepartmentBigSalary.Salary
题目8: 删除重复的电子邮箱
DELETE语句在不指定WHERE子句的时候, 默认是删除表中全部的行。题目指定了两个条件, “删除 Person 表中所有重复的电子邮箱,重复的邮箱里只保留 Id 最小 的那个”, WHERE同时也需要指定两个条件。两个条件, 请参考下面的代码。唯一值的注意的一点是, DELETE本身是更新操作, 所以在FROM需要新建一个派生表, 否则会产生错误(You can’t specify target table ‘Person’ for update in FROM clause)
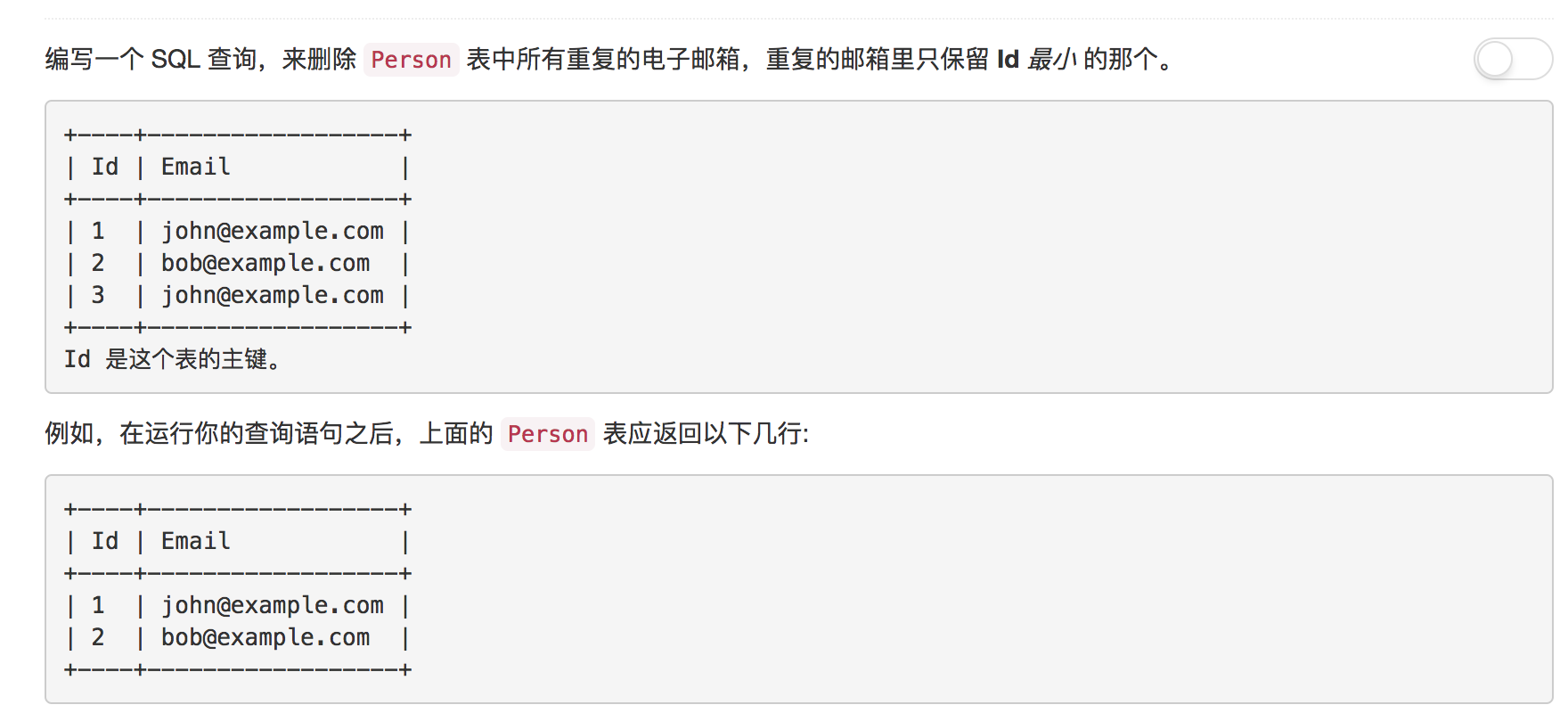
解答
DELETE
FROM Person
WHERE Person.Email IN (
# 条件1: 删除长度大于2的行
SELECT table1.Email
FROM (
SELECT Person.Email AS Email
FROM Person
GROUP BY Person.Email
HAVING COUNT(Person.Email) > 1
) AS table1
) AND Person.Id NOT IN (
# 条件1: 删除长度大于2的行, 但是不包含id最小的行
SELECT table2.id
FROM (
SELECT MIN(Person.Id) AS id
FROM Person
GROUP BY Person.Email
HAVING COUNT(Person.Email) > 1
) AS table2
)
题目9: 上升的温度
本题主要考察了对自联结的使用。如何判断两个相邻的RecordDate的Temperature的大小?通过对同一张表进行JOIN联结, JOIN的ON的条件修改为w1.RecordDate = DATE_SUB(w2.RecordDate,INTERVAL -1 DAY), w1表的RecordDate是w2表RecordDate前一天, w1的每一行关联的w2的每一行其实w1的后一天。
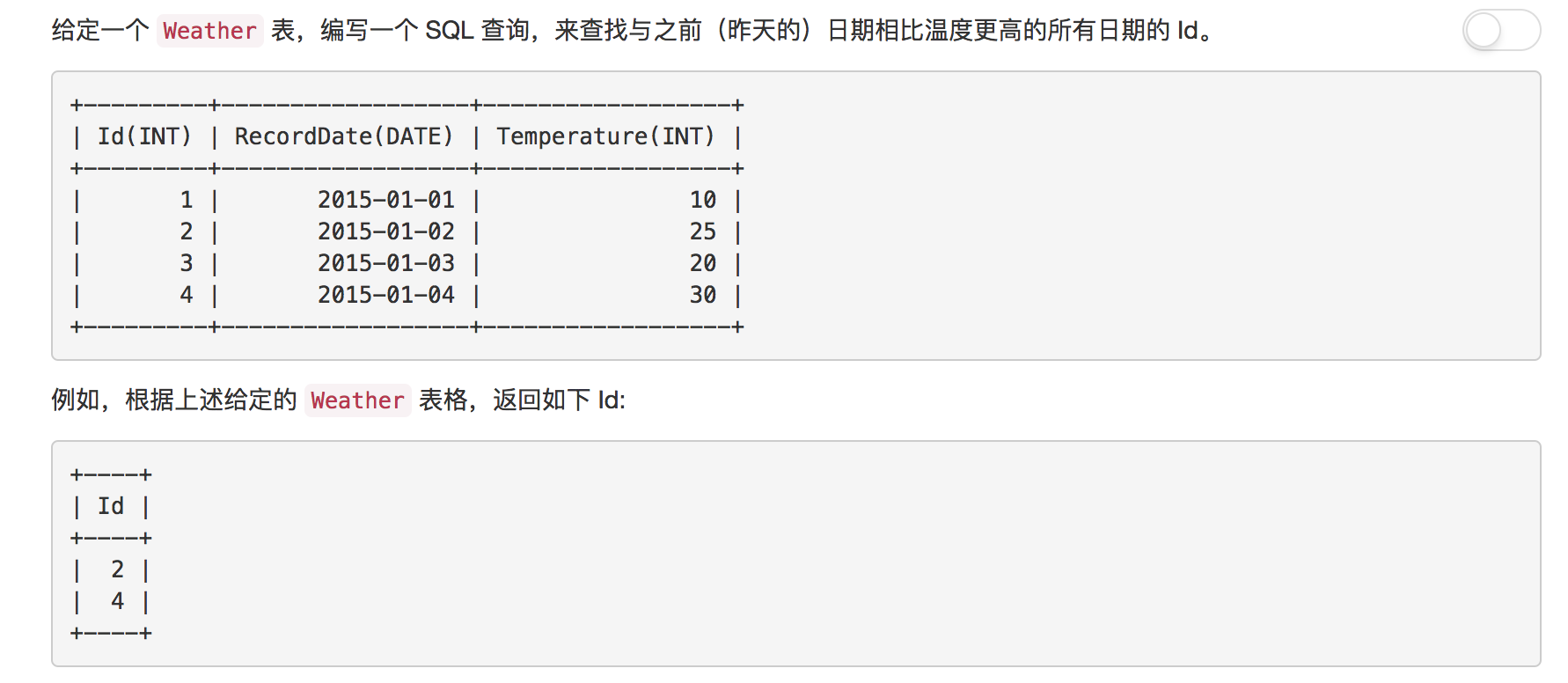
解答
SELECT w1.Id AS Id
FROM Weather AS w1 INNER JOIN Weather AS w2
ON w1.RecordDate = DATE_SUB(w2.RecordDate,INTERVAL -1 DAY)
WHERE w1.Temperature > w2.Temperature
题目10: 大的国家
非常简单的一道题, 这里不在赘述
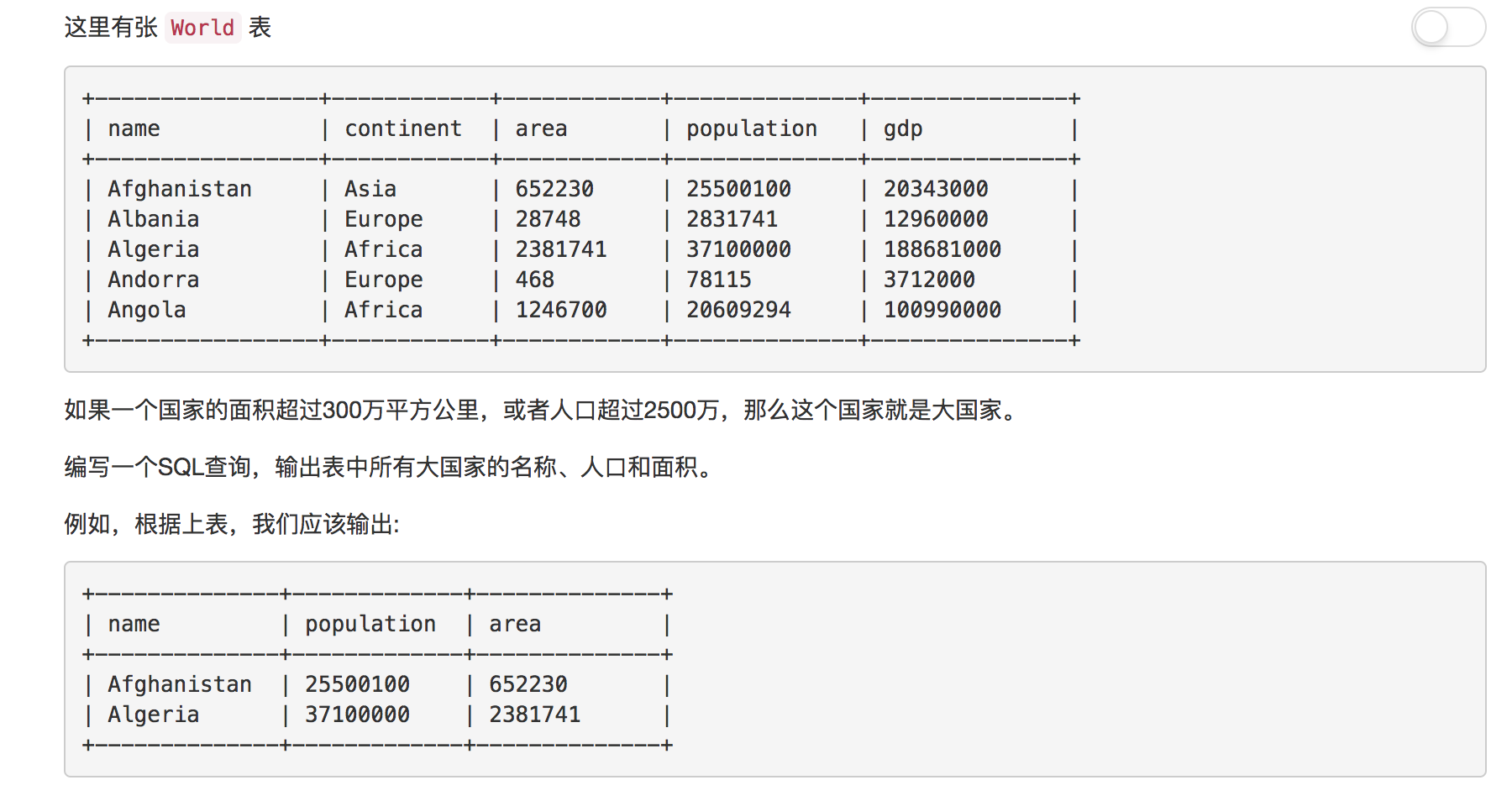
解答
SELECT World.Name AS Name, World.population AS population, World.area AS area
FROM World
WHERE World.population > 25000000 OR World.area > 3000000
题目11: 超过5名学生的课
超过5名学生的课, 本道题目注意考察点在于对GROUP BY去重效果的认知上。
首先子查询的采用嵌套分组。首先使用课程分组然后根据学生进行分组。可以有效去除课程, 学生重复的行。为什么不直接使用学生分组呢?因为这样做会丢失学生的课程信息。在外层的查询中只需要查找中COUNT大于5的课程即可。
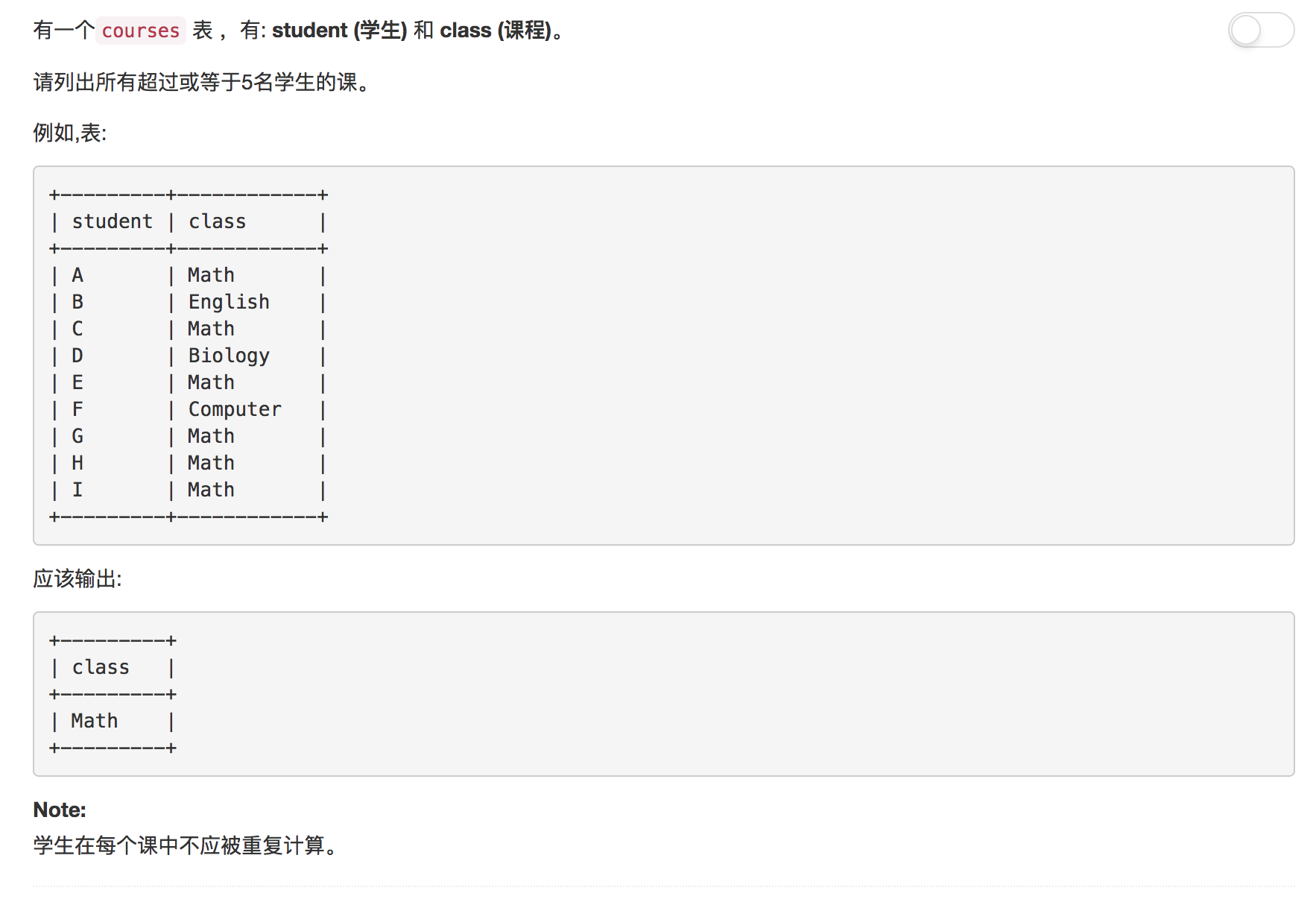
解答
SELECT ClassLength.class FROM (
# 排除了学生和课程重复的行
SELECT courses.class AS class
FROM courses
GROUP BY courses.class, courses.student
) AS ClassLength
GROUP BY ClassLength.class
HAVING COUNT(ClassLength.class) >= 5
题目12: 有趣的电影
本道题目也较为简单, 考察点在于对于奇偶数的判断上, 我们可以使用MySQL的MOD函数。MOD(N, M), MOD函数将返回N/M的余数
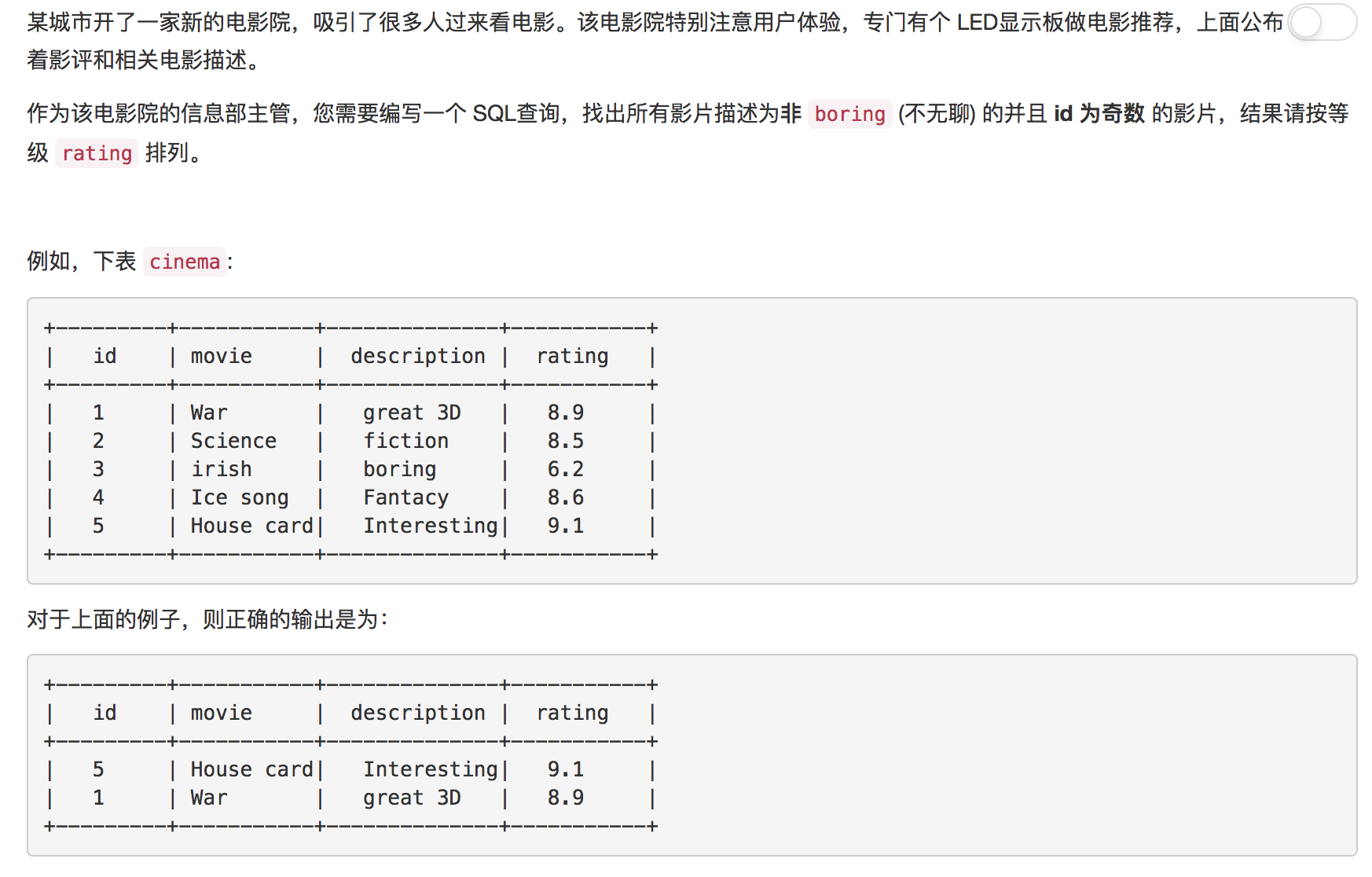
解答
SELECT cinema.id AS id, cinema.movie AS movie, cinema.description AS description, cinema.rating AS rating
FROM cinema
WHERE cinema.description <> 'boring' AND MOD(cinema.id, 2) = 1
ORDER BY rating DESC
题目13: 交换工资
题目本身要求使用一个更新查询,并且没有中间临时表。所以SQL中避免不了需要使用逻辑判断, 这里使用MySQl的CASE WHEN语句
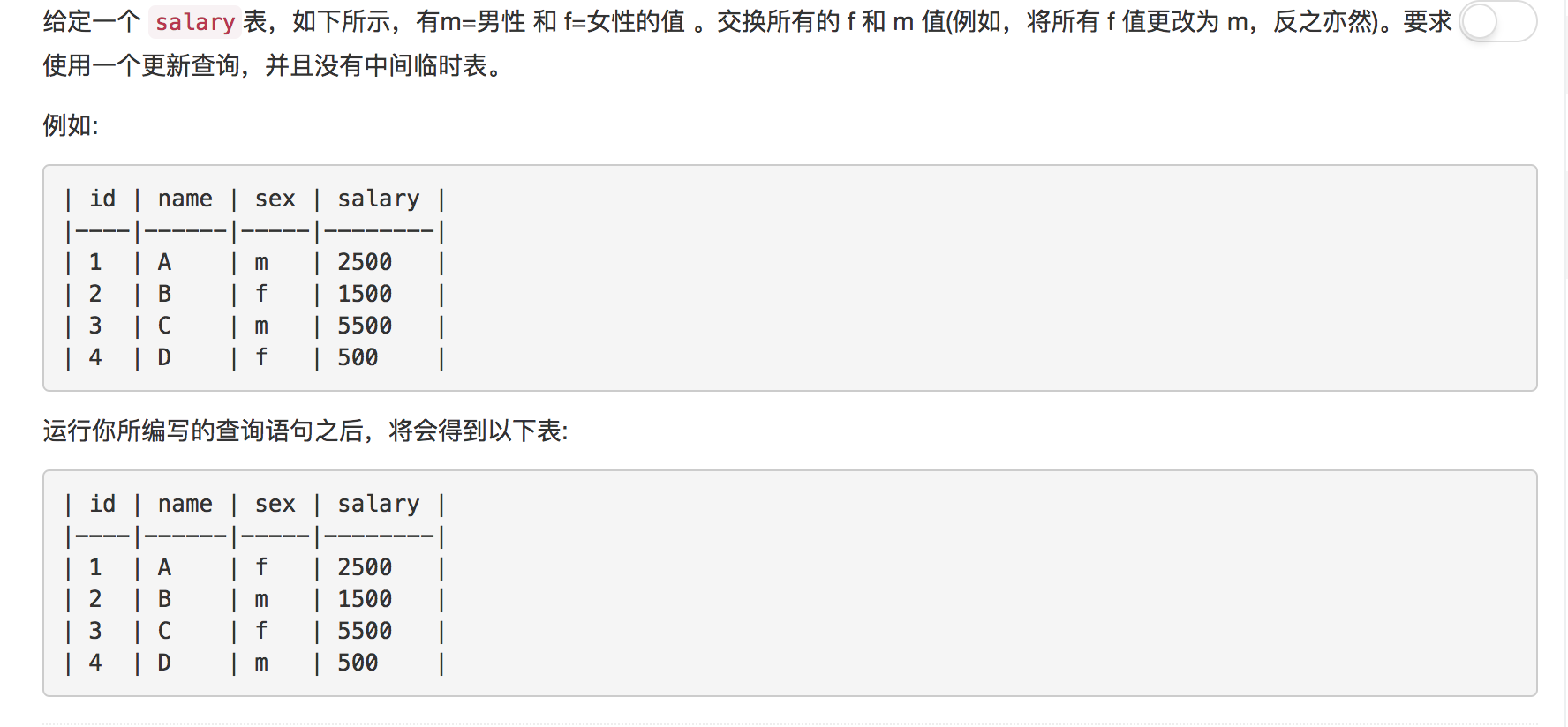
解答
UPDATE salary
SET salary.sex = (
CASE
WHEN salary.sex = 'm' THEN 'f'
WHEN salary.sex = 'f' THEN 'm'
ELSE 'sex'
END
)
题目14: 连续出现的数字
与"上升的温度"的题目类似, 合理的使用自联结, 就可以解答出本题
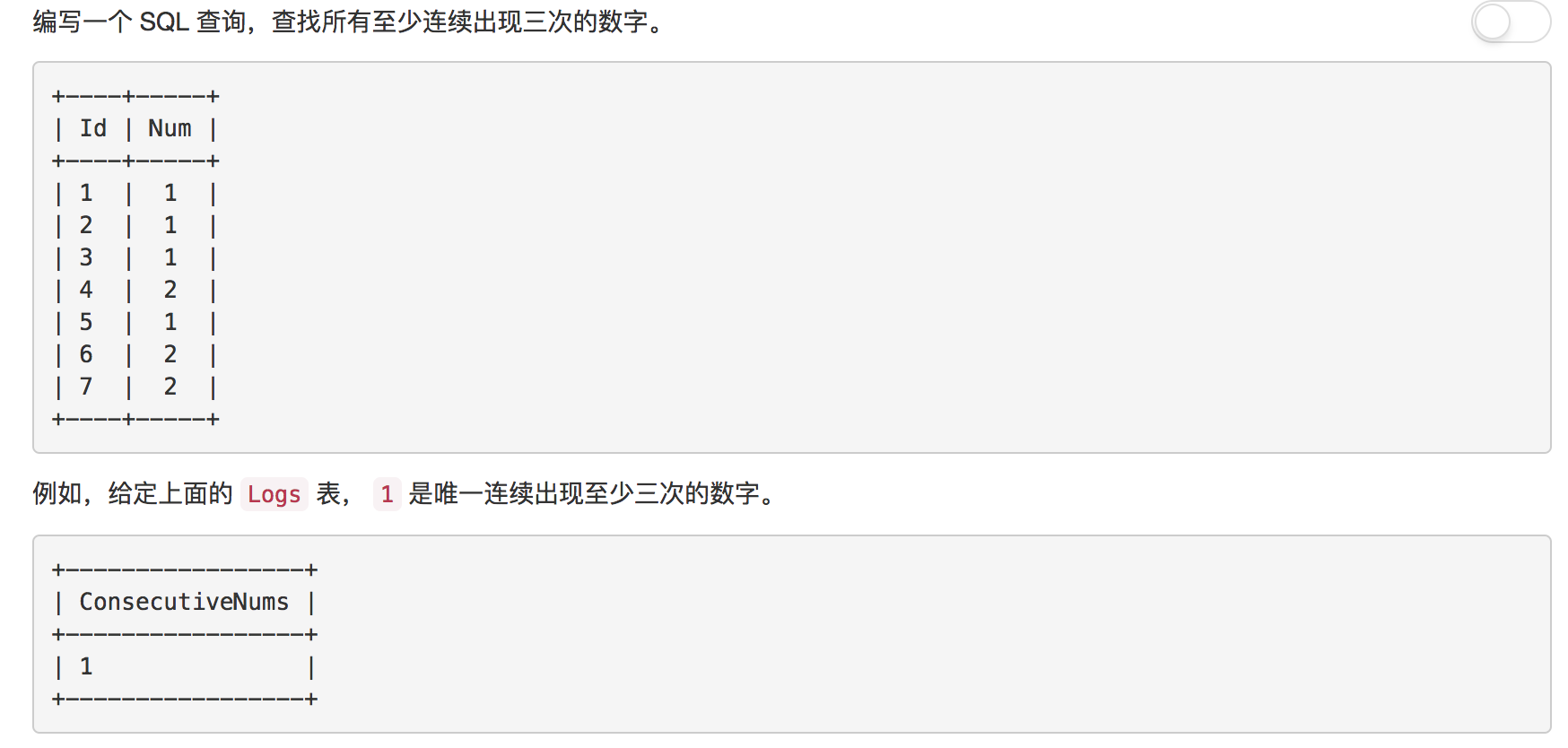
解答
SELECT Consecutive.ConsecutiveNums
FROM (
SELECT l1.Num AS ConsecutiveNums
FROM Logs AS l1 INNER JOIN Logs AS l2 INNER JOIN Logs AS l3
ON l1.id = l2.id - 1 AND l2.id = l3.id - 1 AND l1.id = l3.id - 2
WHERE l1.Num = l2.Num AND l2.Num = l3.Num AND l1.Num = l3.Num
) AS Consecutive
GROUP BY Consecutive.ConsecutiveNums

